P4:Skill 与 Agent 知识管理
Easy Data x AI 课程 · 道篇 · 第四期
Skill 碎片化不是工程问题——它和知识库分散是同一类数据问题。
开场:程序记忆的另一面
上一期我们讲了 Agent 的记忆系统。在三种长期记忆中,程序记忆可能是最容易被忽略、但最有实践意义的一种。
回忆一下:语义记忆存的是“什么是什么”——关于用户的事实;情景记忆存的是“发生了什么”——过去的交互经验;而程序记忆存的是“遇到这种情况该怎么做”——行为规则和工作流程。
我们在 P3 结尾埋了一个伏笔:程序记忆是三种记忆中唯一一种 Agent 可以自我修改的。如果用户多次表达“回答太长了”,Agent 可以给自己加一条“回答要简洁”的规则。这种自我修改能力让程序记忆特别有意思——它不只是被动存储信息,它直接塑造了 Agent 的行为方式。
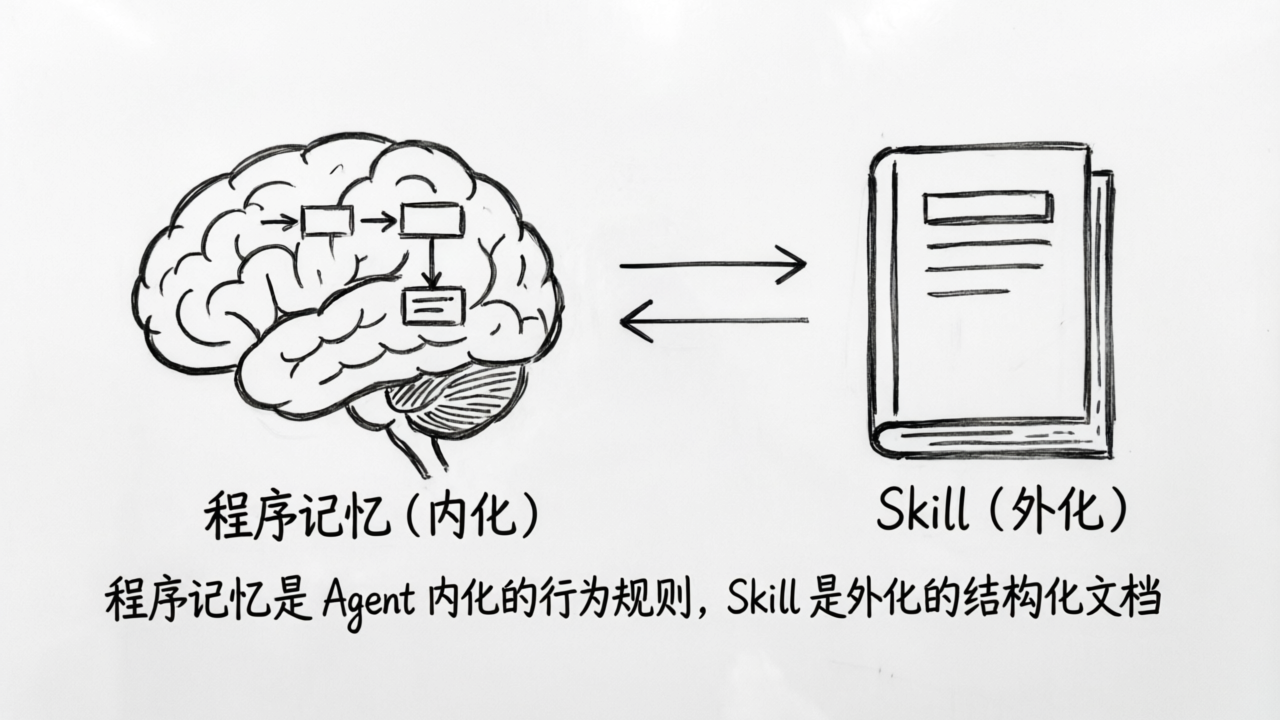
但 P3 讲的是程序记忆的“内在”形态——Agent 内部的一组规则。
今天我们要讲的是程序记忆的“外在”形态——Skill。
你可以这么理解:如果程序记忆是一个人“脑子里”知道该怎么做事的那套经验,那 Skill 就是他把这套经验写成了一份操作手册,放到了书架上,让任何人都可以拿来用。
Skill 是当下 Agent 生态中最热门、但被系统性讨论得最少的概念之一。每个用 AI 编程工具的人都在写 Skill,每个 Agent 平台都有自己的 Skill 机制,但几乎没人退后一步想过:这些 Skill 的管理方式,本身就是一个数据问题。
今天我们来拆解这件事。
第一部分:什么是 Skill
从程序记忆到 Skill
在 P3 中,我们举过程序记忆的例子:
- “用户问代码问题时,先给解释再给示例”
- “回答前先确认用户的技术背景”
- “当遇到多步骤任务时,先列出步骤大纲再逐步执行”
这些规则存在于 Agent 的“脑子里”——通常以 System Prompt 或者模型内化的行为模式呈现。它们发挥作用,但有一个局限:它们是隐式的、通用的、和特定 Agent 绑定的。
Skill 做的事情,是把这类“怎么做”的知识显式化、结构化、独立化。
举个更具体的例子。假设你是一个产品经理,团队里有一个非常优秀的运营同事,他写用户增长方案特别有套路:先做竞品数据分析、再拆解用户分层、然后针对每一层制定差异化策略、最后给出可量化的 KPI。每次他出的方案质量都很高。
这套“套路”存在他的脑子里,这就是他的“程序记忆”。
现在想象他把这套方法论写成了一份详细的文档:“第一步,收集竞品近三个月的核心增长指标;第二步,按行为特征将用户分为以下几个层级……”——写清楚了每一步的操作要点、判断标准、常见陷阱。
这份文档就是一个 Skill。
Skill = 把操作流程、领域规则、成功经验,变成 Agent 可以调用的结构化文档。
有了 Skill,Agent 不再只依赖通用训练知识来回答问题,它可以调用特定领域的专业经验。就像一个刚入职的新员工,如果公司有一套完善的 SOP 手册,他不需要从零摸索,按照手册就能做到八十分的水准。Skill 对于 Agent 的意义也是一样的——它把“怎么做”的经验数据交给了 Agent,让 Agent 在特定领域的表现从“通用水平”跃升到“专家水平”。
Skill 的典型形态
在当前的 Agent 生态中,广义上的 Skill 以各种形式存在:
- Cursor Rules:在 Cursor IDE 中,你可以写
.cursor/rules/下的规则文件,告诉 AI 助手“在这个项目中,React 组件用函数式写法,不用类组件”“所有 API 调用都要有错误处理”“测试文件命名用 xxx.test.ts 格式”。 - Claude Code 的 CLAUDE.md:Claude Code 会读取项目根目录的 CLAUDE.md 文件,里面写着项目的技术栈、代码风格、常用命令等信息。
- SKILL.md 文件:一些 Agent 框架允许用户编写独立的 Skill 文档,描述一个特定能力——比如“如何发布一个 npm 包”“如何进行代码审查”“如何生成符合公司规范的 API 文档”。
- System Prompt 模板:很多团队积累了大量经过验证的 Prompt 模板,本质上也是 Skill——“在做翻译任务时,按照这个 Prompt 模板来操作”。
名字不一样,格式不一样,平台不一样——但它们做的是同一件事:把“该怎么做”的经验知识,以文档的形式提供给 Agent。
理解了这一点,你就明白了 Skill 和 P3 讲的程序记忆之间的关系:Skill 是被外部化、结构化了的程序记忆。程序记忆是 Agent“内化”的行为规则,Skill 是把这些规则“外化”成了可以管理、可以共享、可以检索的文档资产。
这个区别很重要。因为一旦经验变成了文档,它就不再是某个人或某个 Agent 专属的——它变成了可以被管理的数据。而一旦涉及数据管理,我们在前几期课程中讨论过的那些问题,就全都出现了。
Skill 设计规范:像设计 MCP Tool 一样设计 Skill
理解 Skill 是“可以被管理的数据”之后,一个很自然的问题就来了:既然它是数据资产,那它应该怎么写,才方便被检索、被复用、被 Agent 稳定调用?
这里可以借鉴 MCP Tool 的设计思路。
一个 MCP Tool 通常不会只写一段“这是个查询工具”。它会有稳定的工具名、清晰的描述、结构化的输入参数,以及可验证的返回结果。这样 Agent 才能判断:什么时候该用这个工具、调用时要传什么参数、调用失败后该怎么处理。
Skill 也如此。Skill 虽然不是一个可执行函数,但它和 Tool 一样,都会被 Agent “选择”和“调用”。所以一个高质量 Skill 不能只是一篇随手写下来的经验笔记,而应该有相对标准的结构。
最小可用的 Skill,建议至少包含四类信息:
- 命名:让系统能稳定识别它
- 描述:让 Agent 能判断何时使用它
- 参数或输入范围:让 Agent 知道执行任务时需要收集什么
- 示例:让 Agent 理解正确用法和边界
1. 命名:稳定、具体、可检索
Skill 的名字相当于 MCP Tool 的 name。它不只是给人看的标题,也是系统索引、路由和检索时使用的标识。
好的 Skill 名称应该满足三个原则:
- 稳定:一旦被项目或团队引用,就不要频繁改名
- 具体:能看出任务目标,而不是只写一个大而泛的领域名
- 机器友好:尽量使用小写英文、短横线分隔,方便跨系统处理
例如:
name: api-doc-writing
name: npm-package-release
name: college-archive-management不推荐:
name: docs
name: helper
name: 我的超强写文档技能这里的差别和 Tool 命名一样。archive/search 比 doSomething 更容易被 Agent 理解,也更容易被系统维护。Skill 也是同理,名字越稳定、越贴近任务,后续检索和路由越可靠。
2. 描述:写清触发条件
Skill 的 description 很像 MCP Tool 的描述字段。它的核心作用是帮助 Agent 判断:当前用户请求是否应该加载这个 Skill。
好的描述应该包含三件事:
- 适用任务:这个 Skill 解决什么类型的问题
- 触发场景:用户说什么、做什么时应该考虑使用
- 边界范围:什么情况不应该使用
例如:
description: 当用户需要按团队规范编写或修改 API 文档时使用,适用于接口说明、请求参数、响应示例和错误码整理;不用于生成后端接口代码。这比下面这种描述更有用:
description: 帮助写 API 文档。第二种写法太宽。Agent 可能不知道它是用于“写新文档”、还是“检查旧文档”、还是“生成 OpenAPI schema”。描述越模糊,检索和调用就越容易偏。
可以把 description 看成 Skill 的“语义入口”。当 Skill 库变大以后,系统很可能先用名称和描述做召回,再决定是否加载正文。因此描述不是装饰,它直接影响 Skill 能不能被找到。
3. 参数:声明任务需要哪些输入
MCP Tool 有明确的 inputSchema,告诉 Agent 调用工具时必须传哪些参数、每个参数是什么类型、哪些是必填项。Skill 不一定像 Tool 一样直接执行,但它同样需要说明:完成这个任务时,Agent 应该关注哪些输入。
在 Skill 中,可以用 inputs、required_fields、optional_fields、constraints 等字段描述输入范围。
例如:
inputs:
required:
- endpoint_path
- http_method
- request_params
- response_schema
optional:
- auth_requirement
- error_codes
- example_request
- example_response这样 Agent 就知道:如果用户说“帮我写一下这个接口文档”,但没有提供请求参数和响应结构,它不应该直接编造,而应该继续追问或读取相关代码。
参数设计有三个要点:
- 区分必填和可选:不要把所有信息都写成“最好有”,否则 Agent 不知道什么时候可以继续
- 说明参数来源:有些参数来自用户输入,有些来自代码仓库,有些来自工具查询结果
- 避免把业务实现写进 Skill:Skill 只说明需要什么信息和何时调用工具,不替代后端校验、权限判断或数据写入
这一点和 MCP Tool 的边界非常像:Tool 的 schema 负责约束输入,但真正的业务规则仍然要在工具或服务端执行。Skill 也一样,它负责约束 Agent 的行为,但不应该承担全部业务逻辑。
4. 示例:用最小样例校准行为
Skill 需要示例,就像 MCP Tool 文档里通常会给出调用样例。示例的作用不是堆材料,而是校准 Agent 对“正确执行方式”的理解。
一个好的 Skill 示例应该尽量短,但要覆盖关键边界:
- 什么样的用户请求会触发这个 Skill
- Agent 应该如何判断缺失信息
- 信息足够时应该如何推进
- 哪些行为是禁止的
例如:
examples:
- user: 帮我给 POST /api/orders 写接口文档
agent_behavior: 检查是否已有请求参数、响应结构和错误码;缺失时先追问或读取代码,不直接编造字段。
- user: 直接生成一个订单接口文档,字段你看着写
agent_behavior: 拒绝编造业务字段,说明需要 endpoint、参数来源或代码上下文。注意,示例不是固定问答脚本。它不要求 Agent 逐字复述,而是提供行为参照。好的示例应该像测试用例一样,帮助我们验证 Skill 是否会在关键场景中稳定工作。
一个推荐的 Skill 模板
综合起来,一个 Skill 可以采用下面这样的结构:
name: api-doc-writing
description: 当用户需要按团队规范编写或修改 API 文档时使用,适用于接口说明、请求参数、响应示例和错误码整理;不用于生成后端接口代码。
goal:
生成结构完整、字段可信、符合团队格式的 API 文档。
inputs:
required:
- endpoint_path
- http_method
- request_params
- response_schema
optional:
- auth_requirement
- error_codes
- example_request
- example_response
tools:
- code/search
- file/read
- docs/update
constraints:
- 缺少请求参数或响应结构时,先追问或读取代码,不直接编造
- 如果工具查询结果和用户描述冲突,先说明冲突并请求确认
- 不修改接口实现代码,只生成或更新文档
examples:
- user: 帮我给 POST /api/orders 写接口文档
agent_behavior: 先确认接口路径、方法、请求参数和响应结构;缺失时读取代码或追问。
- user: 字段你随便补一下
agent_behavior: 不编造字段,要求提供代码上下文或业务说明。这个模板和 MCP Tool 规范的精神是一致的:用稳定名称做识别,用清晰描述做触发,用结构化参数做约束,用示例校准行为。
当然,不同平台的 Skill 文件格式可能不一样。有的写在 SKILL.md,有的写在 .cursor/rules/,有的写进系统提示词。但无论外层格式如何变化,底层都应该尽量保留这四类信息。否则 Skill 就会退化成一段散文:人读着有感觉,Agent 用起来不稳定,系统也很难检索和管理。
第二部分:碎片化困境——当前 Skill 管理的真实现状
了解了 Skill 是什么之后,让我们看看它在实际使用中面临的最大问题。
一个熟悉的场景
你可能有这样的经历:
你在 Cursor 里花了不少时间,给一个项目写了一套完善的 Rules。这些规则涵盖了项目的技术栈约定、代码风格、目录结构、常见的坑和最佳实践。有了这套 Rules,AI 助手在这个项目里写出来的代码质量明显提高了——它知道用哪个组件库、知道错误处理的标准模式、知道测试应该怎么写。
然后你换了一个新项目。
一切归零。
你在新项目里开一个新窗口,AI 助手又变回了那个“什么都不知道”的状态。你之前积累的那些规则、那些经验、那些踩坑总结——全都留在了上一个项目的 .cursor/rules/ 目录里。你想用?手动复制粘贴。
更头疼的是,你不只用一个 AI 工具。你在 Cursor 里有一套规则,在 Claude Code 里有一份 CLAUDE.md,可能还在 ChatGPT 里保存了几个自定义 GPT 的 Prompt。这些经验散落在三个完全不同的平台上,格式不兼容,互相看不见。
你的 Cursor Rules 没法在 Claude Code 里用。你的 CLAUDE.md 没法在 Cursor 里用。你在 ChatGPT 里验证过的有效 Prompt,想用到其他工具里只能靠手动复制。
这不是你一个人的问题
你以为这只是个人用户的烦恼?企业里的情况更严重。
想象一个产品团队。前端工程师 A 在自己的 Cursor 里写了一套前端开发 Rules,涵盖了组件规范、状态管理方案、性能优化技巧。后端工程师 B 在自己的 Claude Code 里积累了后端 API 设计的最佳实践。测试工程师 C 有一份自己整理的测试策略 Prompt 模板。产品经理 D 有一套用来做竞品分析的 GPT 自定义指令。
每个人的经验都很有价值。但它们分别存在四个人的电脑里、四个不同的工具里、四种不同的格式中。
这就像一家公司里,每个部门的操作流程都写在各自负责人的私人笔记本上,没有共享的 wiki、没有统一的知识库。 新人入职,没有任何地方可以系统地了解“我们部门的最佳实践是什么”。某个老员工离职了,他笔记本里十年积累的经验就跟着他走了。想跨部门协作?先花半天互相说明各自的做事方式。
这个类比你可能觉得很熟悉——因为这是很多公司在“没有知识管理”时代经历过的痛。而现在,同样的痛正在 AI 工具的 Skill 管理上重演。
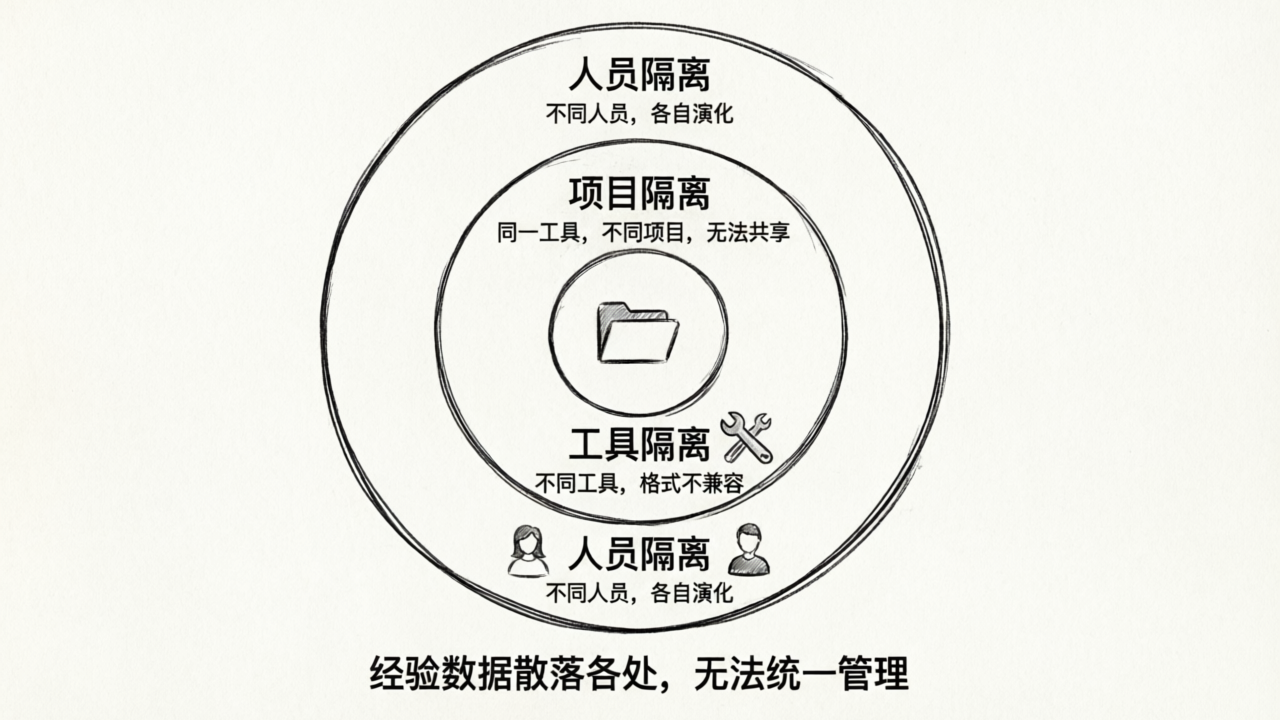
碎片化的三个层面
让我们把这个问题拆得更清楚。Skill 碎片化发生在三个层面:
第一层:项目隔离。 同一个人、同一个工具,但不同项目之间的 Skill 无法自动共享。你在项目 A 积累的规则,开新项目 B 的时候需要手动搬运。有些通用规则(比如“代码要有类型注解”“错误信息用中英双语”)在每个项目里都有用,但你每次都要重新配置一遍。
第二层:工具隔离。 不同 AI 工具之间的 Skill 格式不兼容。Cursor 的 Rules 是 .mdc 文件存在 .cursor/rules/ 里;Claude Code 读的是项目根目录的 CLAUDE.md;ChatGPT 的自定义指令是一段纯文本。即使描述的是同一条规则,你也得用三种不同的方式写三遍。
第三层:人员隔离。 团队成员之间的 Skill 无法便捷共享。你写了一条特别好的规则,想分享给同事,怎么办?发个消息,把文件内容贴过去。同事收到后,手动粘贴到自己的工具里。如果这条规则后来需要更新呢?再发一次消息。一个团队十个人,每个人的规则都在自己的机器上各自演化,半年后可能已经分叉成了十个版本。
三个层面加在一起,结果就是:团队积累的 AI 使用经验,变成了一堆散落在不同地方的碎片,无法被系统性地检索、共享和复用。
第三部分:Skill 的发现与检索——当 Skill 多了以后
碎片化是一个“管理”层面的问题。现在让我们看另一个紧密相关的问题:当 Agent 有几十个甚至上百个可用的 Skill 时,它怎么知道在当前场景下应该用哪一个?
一个朴素的方法
最简单的做法是全部加载——把所有 Skill 文档一股脑塞进 Agent 的上下文窗口里,让 Agent 自己判断哪个相关。
这个方法在 Skill 很少的时候确实管用。你有三五条规则,每条几百字,全部放进 System Prompt 里,Agent 读一遍就知道该遵循什么。
但当 Skill 数量增长到几十个、内容总量达到几万字甚至更多的时候,问题就来了:
第一,上下文窗口有限。F1 里讲过,大模型的上下文窗口就是一张工作台,空间有限。把几十份 Skill 文档全摊在工作台上,留给用户实际问题的空间就不够了。
第二,注意力被稀释。即使上下文窗口够大,研究也表明,当输入文本过长时,模型对“中间部分”的信息关注度会下降。你最需要的那条 Skill 如果恰好被淹没在一大堆不相关的规则中间,Agent 很可能会忽略它。
第三,不相关的 Skill 可能造成干扰。如果你在问一个前端组件的问题,Agent 的上下文里却塞着一堆后端数据库操作的规则,这些不相关的规则不仅占空间,还可能让 Agent 的回答偏离方向。
本质上是一个检索问题
怎么解决?答案你可能已经猜到了——这是一个检索问题。
Agent 面对一个用户请求时,需要从可用的 Skill 库中,找到与当前请求最相关的那几个 Skill,把它们加载到上下文中,而不是把所有 Skill 都加载。
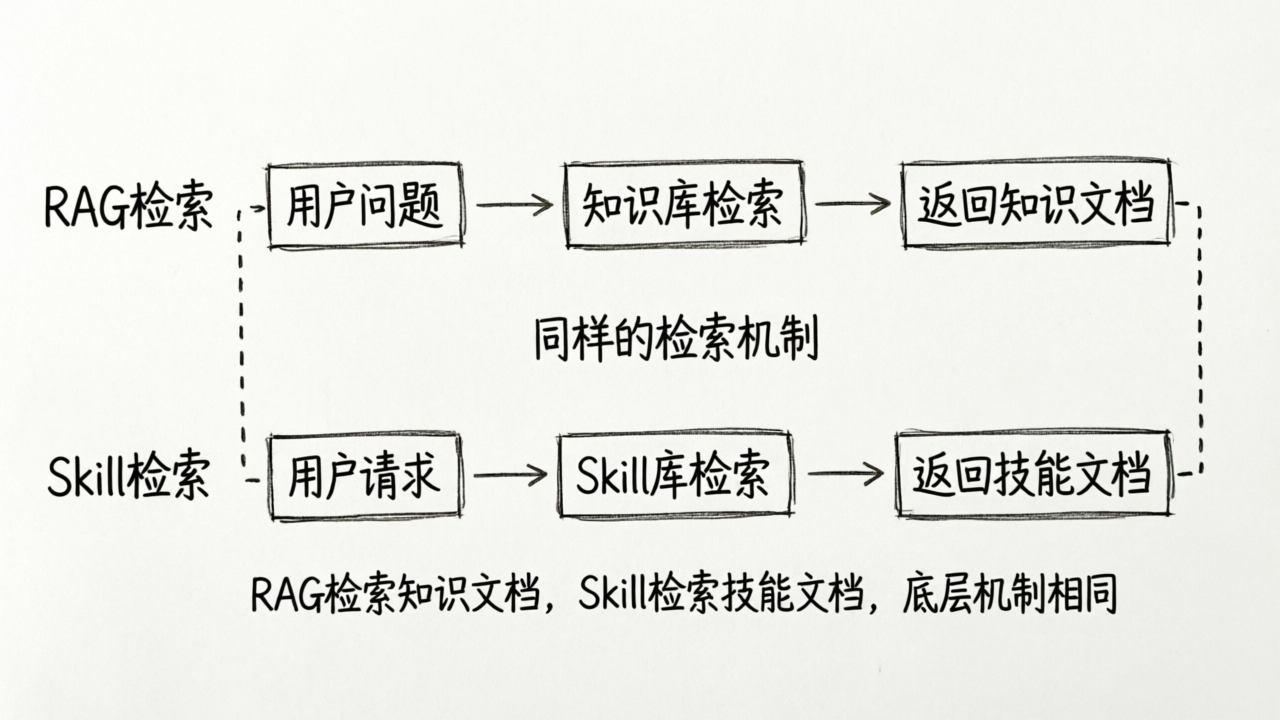
这个过程,和 P2 讲的 RAG 是一模一样的机制。
P2 里,RAG 做的事情是:用户提了一个问题 → 从知识库中检索最相关的文档片段 → 把这些片段交给模型来生成回答。
Skill 检索做的事情是:用户提了一个请求 → 从 Skill 库中检索最相关的 Skill 文档 → 把这些 Skill 交给 Agent 来指导行为。
区别只是检索的对象不同——RAG 检索的是“知识文档”,Skill 检索的是“技能文档”。但底层的检索机制完全相同:都是基于语义相似度,从一个文档库中召回最相关的内容。
甚至 P2 里讨论过的那些检索策略问题,在 Skill 场景中也一样存在。比如:
- 混合检索的必要性:如果用户说“帮我发布一个 npm 包”,纯语义搜索可能会返回“帮我发布一个 Python 包”的 Skill——因为在语义空间中,它们都是“发布包”这个主题。但你需要的是精确匹配“npm”这个关键词的 Skill。P2 讲过,混合检索(语义 + 关键词)可以解决这个问题。
- Agentic 检索决策:有时候 Agent 需要判断“这个请求需不需要调用 Skill”。一个简单的闲聊不需要任何 Skill;但一个“帮我按照公司规范写一份 API 文档”的请求,就需要去检索“API 文档写作规范”这个 Skill。P2 里讨论的 Agentic RAG 的“要不要搜”“搜哪里”“搜到的结果够不够好”的决策逻辑,在 Skill 检索中同样适用。
P2 的搜索策略讨论,在这里完全复用。 这不是巧合——这正是我们这门课一直在强调的核心判断:Agent 的各种能力,拆到底都是数据的存储与检索。RAG 是知识数据的检索,记忆是用户数据的检索,Skill 是经验数据的检索。底层机制相通,只是数据类型不同。
第四部分:回到数据视角——Skill 碎片化的根因
现在让我们退后一步,用数据的视角来审视 Skill 碎片化这个问题。
在 P2 中,我们讨论过一个核心判断:知识库分散、内容残缺、格式混乱——这些数据层的问题,是 RAG 效果不好的首要原因。 大多数“AI 答得不好”的情况,不是模型不行,而是模型根本没拿到正确的数据。
现在,把这个判断中的“知识库”替换成“Skill”,你会发现一模一样的逻辑成立:
Skill 分散在不同的文件系统、不同的项目目录、不同的平台配置中——无法被统一检索、无法被团队共享、无法被跨 Agent 复用。这不是一个工程问题,这是一个数据管理问题。
具体来说:
- 知识库数据分散 → RAG 检索不到正确内容 → AI 回答质量差
- Skill 数据分散 → Agent 找不到最佳技能 → Agent 行为不够专业
同一类问题,同一个根因——经验数据没有被结构化地管理。
P2 里那个经典的案例:一家公司的 Agent 回答不好,不是模型不够聪明,而是知识库里缺了一半的内容,另一半是半年前的旧版本。问题出在数据层。
Skill 面临的是相同处境。你的团队可能已经积累了大量高质量的 Skill——有效的编程规则、验证过的 Prompt 模板、特定领域的操作流程。但这些经验数据散落在每个人的电脑上、每个项目的配置目录里、每个 AI 工具的专属格式中。
数据存在,但不可检索、不可共享、不可复用——和“知识库里有内容但 Agent 检索不到”是一回事。
这个认识很重要,因为它改变了我们思考解决方案的方向。如果你把 Skill 碎片化当成一个“工程问题”,你会想着去写同步脚本、做格式转换器、建文件监听服务——每次某个工具出了新格式你就要适配一次,永远在追赶。
但如果你把它当成一个“数据管理问题”,解题思路就清晰了:把 Skill 当作一种需要被统一存储、索引、检索的数据资产来管理——就像你管理知识库一样管理技能库。
我们的思考
我们观察到一个越来越明显的趋势:开发者正在同时使用多个 AI 编程助手。
这不是什么预测——这已经是现实了。很多开发者日常工作中会交替使用 Cursor、Claude Code、Windsurf,甚至还有 GitHub Copilot、各种终端 AI 工具。每个工具有各自的优势:有的更擅长代码补全,有的更擅长复杂推理,有的在特定语言或框架上表现更好。但这带来了一个非常现实的问题:每个助手的 Skill 和记忆都是完全孤立的。
你在 Cursor 里花了两周教会了它你的项目规范——React 用函数组件、状态管理用 Zustand、API 层用 tRPC。然后你切到 Claude Code 去做一个复杂的重构任务。Claude Code 对这一切一无所知。你得重新告诉它所有这些约定。等你在 Claude Code 里积累了新的经验(比如重构过程中发现了一些需要注意的模式),这些经验又回不到 Cursor 里。
每一个 AI 助手都在各自的孤岛上积累经验,孤岛之间没有桥梁。
这让我们开始思考一个方向:如果 Skill 文档不是存在各个工具的本地配置里,而是存在一个统一的、可检索的数据层中——会怎样?
设想一下这样的场景:
你的所有 Skill——无论是编程规范、Prompt 模板、操作流程、领域知识——都存储在一个统一的技能知识库中。当你在 Cursor 里工作时,Cursor 可以从这个知识库中语义检索到与当前任务最相关的 Skill,自动加载到上下文中。当你切到 Claude Code 时,Claude Code 也从同一个知识库检索。当你的同事开了一个新项目时,他也能检索到团队共享的最佳实践。
Skill 不再绑定于特定的工具、特定的项目、特定的人——它变成了团队级别的可检索知识资产。
这就像从“每个人把操作流程写在自己的笔记本上”进化到“公司有一个统一的知识管理平台”。当年企业知识管理领域走过的路——从分散的个人文档到 Confluence、Notion 这样的统一平台——Agent 的 Skill 管理也需要走一遍。
坦率地说,这个方向目前还没有成熟的解决方案。行业还处在很早期的阶段——大多数人甚至还没有意识到 Skill 碎片化是一个需要系统性解决的问题,大家还在手动复制粘贴文件,觉得“这就是现在的用法”。
但路径是清晰的:
- Skill 需要被当作数据资产来管理,而不是散落在文件系统里的配置文件
- Skill 检索需要语义理解——Agent 应该能根据当前任务的语义,动态匹配最佳的 Skill,而不是预先指定
- Skill 需要跨工具、跨项目、跨团队共享——一个统一的检索层,让不同的 Agent 都能访问
本质上,我们在讨论的是:给 Agent 的技能建一个“可检索的知识库”。
这和 P2 讲的给 Agent 建知识库、P3 讲的给 Agent 建记忆系统,是完全一致的思路。知识库管理的是“事实数据”,记忆系统管理的是“用户数据”,Skill 知识库管理的是“经验数据”。底层的数据管理逻辑是相通的——存储、索引、检索、更新、权限控制——只是数据的类型不同。
这正是我们团队在探索的方向。如果 seekdb 能成为 Agent 的通用数据层——不仅存知识、存记忆,还能存 Skill——那 Agent 生态中的数据碎片化问题就有了一个统一的解法。我们还在路上,但每走一步都更确信:Agent 基础设施的下一个重要问题,在数据层。
回到程序记忆
让我们把 P3 和 P4 串起来。
P3 讲的是 Agent 的记忆系统——Agent 需要记住关于用户的事实(语义记忆)、过去的经验(情景记忆)、以及行为规则(程序记忆)。
P4 讲的是 Skill——Agent 需要调用的结构化经验知识。
程序记忆和 Skill,是同一件事的两面。 程序记忆是 Agent “内化”的行为规则——它通过和用户的交互逐渐学到“该怎么做”。Skill 是“外化”的行为规则——由人类显式地编写,提供给 Agent 调用。
一个完整的 Agent 行为系统,需要两者兼备:
- 程序记忆负责个性化的、从交互中学到的行为适应——“这个用户喜欢简洁回答”“这个项目的测试习惯是先写 happy path 再写 edge case”
- Skill负责通用的、从专业知识中提炼的行为指导——“发布 npm 包的标准流程”“写 API 文档的最佳实践”“处理用户投诉的话术模板”
程序记忆让 Agent 越来越“懂你”,Skill 让 Agent 越来越“专业”。两者共同决定了 Agent 在特定领域的表现水平。
从 Skill 到 MCP:为什么需要标准化协议
讲到这里,Skill 已经完成了一个很重要的角色:它把程序记忆从 Agent 内部拿出来,变成了可编写、可管理、可检索、可复用的经验数据。
但这还没有解决另一个问题:当这份经验需要被不同 Agent 客户端统一调用时,应该怎么做?
比如一个 code-review Skill,里面沉淀了代码审查的目标、输入范围、检查清单和输出格式。Claude Code 可以把它放在 .claude/skills/ 中,Cursor 可以把它放在 .cursor/skills/ 或 Rules 中,Codex 可以把它放在 .agents/skills/ 中。对人来说,这些内容表达的是同一套经验;但对客户端来说,它们仍然是不同目录、不同加载机制、不同触发方式下的本地文档。
这说明 Skill 解决的是“怎么做”的问题,却不天然解决“怎么被不同客户端发现和调用”的问题。Skill 更像一份任务说明书:它告诉 Agent 代码审查应该关注正确性、可维护性、安全性和测试覆盖,也告诉 Agent 应该按严重程度输出问题。但如果我们希望这个能力像工具一样被 Claude、Cursor、Codex 等客户端统一发现、统一传参、统一调用,就需要一层标准化接口。
这就是 MCP 适合出现的位置。
MCP(Model Context Protocol)不是要替代 Skill,而是把稳定、通用、边界清晰的 Skill 进一步封装成可调用的工具。可以这样理解它们之间的关系:
Skill:沉淀任务经验,描述“这件事应该怎么做”
MCP Tool:定义标准化调用接口,描述“这个能力应该怎么被调用”
MCP Server:承载并暴露一个或多个 Tool
Agent 客户端:发现 Tool、组织参数、调用 Tool、使用返回结果当一个 Skill 还在快速迭代时,直接写成文档最灵活;当它已经足够稳定,并且需要跨客户端、跨项目、跨团队复用时,就可以考虑 MCP 化。比如 code-review 这类任务,输入通常是 diff 或 PR 上下文,检查维度相对稳定,输出格式也可以结构化,就很适合从 Skill 进一步包装成 MCP Tool。
所以,P4 到这里完成的是产品和数据视角的铺垫:Skill 是可管理的经验数据。下一步,到了 X5 的扩展实战,我们会把这个观点落到代码里:从零实现一个最小 MCP Server,把 code-review Skill 包装成 review_code_diff Tool,并让不同 Agent 客户端通过标准协议调用它。
课后行动
盘点你的团队当前使用的 AI 工具,完成以下练习:
列出所有 AI 工具的 Skill/规则/指令:你的团队在用哪些 AI 工具?每个工具里有没有自定义的 Rules、Instructions、Prompt 模板?它们分别存在哪里?
统计碎片化程度:
- 这些 Skill 分散在多少个不同的地方?(多少个工具、多少台机器、多少个项目目录)
- 有没有不同的人分别维护着功能重叠但内容不同的 Skill?
- 团队新成员加入时,有没有一个统一的地方可以获取所有已有的最佳实践?
思考两个问题:
- 如果某个同事的 Skill 特别好用,现在要分享给整个团队,最快的方式是什么?这个方式的痛点是什么?
- 如果要建一个“团队 Skill 知识库”,让所有 AI 工具都能检索和调用,你认为最大的障碍是什么?
把你的盘点结果带到下一期。P5 我们将进入综合案例与度量——用一个完整的场景把 P1 到 P4 的内容串在一起,看看数据视角如何贯穿 Agent 产品的全生命周期。
延伸阅读
如果你对本期提到的概念想做进一步了解,以下是一些推荐资源:
- CoALA 论文中的程序记忆:Cognitive Architectures for Language Agents,论文中对程序记忆(Procedural Memory)的定义和分析,是理解 Skill 概念的理论基础
- Cursor Rules 文档:Cursor IDE 的 Rules 机制是当前最广泛使用的 Skill 实践之一,了解它的设计可以帮你理解 Skill 在实际产品中的形态
- Anthropic 的 Claude Code 最佳实践:Claude Code 的 CLAUDE.md 和 Memory 机制展示了另一种 Skill 管理思路
- 企业知识管理的演进历史:从个人文档到 SharePoint 到 Confluence 到 Notion,企业知识管理走过的路径,对理解 Skill 管理的未来方向有很好的参照价值
本节补充内容:Skill 互操作——同一个 Skill 如何在不同 Coding Agent 中落地
前面几节课中,我们已经反复看到一个事实:Agent 的能力不是凭空出现的,而是由工具、数据、记忆和执行流程共同组成的。
如果说 Tool Use 解决的是“Agent 如何调用外部能力”,Memory 解决的是“Agent 如何记住经验”,那么 Skill 解决的就是另一个问题:
当我们已经验证出一套有效的任务流程后,如何把它沉淀下来,并在不同的 AI Coding 工具中重复使用?
Skill 可以理解为一种“可复用的任务经验包”。它通常包含任务说明、适用场景、输入输出、执行步骤、检查清单、示例和必要的辅助文件。和普通 Prompt 不同,Skill 不是一次性的对话,而是可以被项目、团队或工具长期复用的工作流。
但是,不同 AI Coding 工具对 Skill 的承载方式并不完全相同。Claude Code、Cursor、GitHub Copilot 和 Codex 都可以沉淀可复用任务经验,但它们在文件位置、触发方式、上下文注入方式和协作入口上存在差异。
因此,跨平台 Skill 互操作不应简单理解为“把同一个文件原封不动复制到所有工具里”,而更适合拆成两层:
公共 Skill 层:任务目标、触发条件、输入输出、执行步骤、检查清单、示例
平台适配层:不同工具中的文件路径、触发机制、上下文机制和协作入口下面用一个最常见的示例来说明:code-review Skill。
1. 为什么选择 code-review 作为示例 Skill
代码审查是最适合作为跨平台 Skill 示例的任务之一。原因是它不依赖特定业务领域,输入通常都是代码 diff、PR、staged changes 或 changed files,输出也可以统一为结构化的审查意见。
一个通用的 code-review Skill 可以这样定义:
---
name: code-review
description: Review code changes, diffs, or pull requests for correctness, maintainability, security, tests, and project conventions. Use when the user asks to review code, inspect a PR, or check local git changes before merging.
---
# Code Review Skill
## Goal
Review code changes systematically and produce actionable findings.
## Inputs
- Git diff, staged changes, branch diff, or pull request context
- Project conventions
- Test results, CI logs, or changed files when available
## Review Checklist
1. Correctness: logic errors, edge cases, regressions
2. Maintainability: structure, naming, duplication, complexity
3. Security: injection, auth, secret leakage, unsafe file/network operations
4. Tests: missing tests, brittle tests, incorrect assertions
5. Compatibility: API changes, migrations, dependency impact
6. Project conventions: style, architecture, existing patterns
## Output Format
Return findings grouped by severity:
- Critical: must fix before merge
- Major: should fix before merge
- Minor: improvement or style issue
- Positive notes: things done well
Each finding should include:
- File / location
- Problem
- Why it matters
- Suggested fix这段内容就是“公共 Skill 层”。它描述了任务本身,不绑定任何具体平台。接下来要做的是把它适配到不同 Coding Agent 中。
2. Claude Code:以 SKILL.md 为核心的原生 Skill 包
在 Claude Code 中,Skill 通常以目录形式存在,核心入口是 SKILL.md。对于 code-review 这个示例,可以放在项目目录中:
.claude/
└── skills/
└── code-review/
├── SKILL.md
├── examples/
│ └── review-output.md
└── scripts/
└── collect-diff.sh其中:
SKILL.md写代码审查步骤、检查清单和输出格式;examples/review-output.md提供期望输出示例;scripts/collect-diff.sh可以用于收集当前分支 diff。
Claude Code 的优势是 Skill 结构清晰,适合沉淀完整工作流。对于代码审查这类多步骤任务,它不仅能保存说明,还可以把示例、脚本、模板和参考资料一起放进 Skill 目录中。
在调用流程上,可以理解为:
用户提出 review 需求
↓
Claude 根据 skill description 判断是否适用
↓
加载 code-review/SKILL.md
↓
必要时读取 examples、scripts 等支持文件
↓
结合当前项目上下文和 git diff 进行审查
↓
输出结构化 review findings如果用户希望显式调用,也可以直接使用对应的 Skill 名称来触发。
需要注意的是,不同平台对 frontmatter 字段的要求并不完全一致。例如在 Claude Code 的普通 Skill 目录中,命令名主要来自目录名,description 用于帮助 Claude 判断何时自动使用这个 Skill;而 Codex 和 GitHub Copilot 对 name、description 的要求更明确。为了方便跨平台迁移,本文示例统一保留 name 和 description,但这不意味着每个平台都以完全相同的方式强制解析这些字段。
3. Codex:同样接近原生 SKILL.md Skill 包
Codex 在 Skill 形态上和 Claude Code 比较接近,核心同样是一个包含 SKILL.md 的目录。对于 code-review,可以放在仓库中的:
.agents/
└── skills/
└── code-review/
├── SKILL.md
├── references/
│ └── review-guidelines.md
└── scripts/
└── collect-diff.sh其中 SKILL.md 可以复用前面的公共 Skill 定义:
---
name: code-review
description: Review code changes, diffs, or pull requests for correctness, maintainability, security, tests, and project conventions.
---
# Code Review Skill
Review changed code systematically.
Steps:
1. Inspect the diff and changed files.
2. Check correctness, edge cases, and regression risks.
3. Check tests and CI impact.
4. Check security and maintainability.
5. Return findings grouped by severity.Codex 的调用流程可以概括为:
Codex 启动或进入仓库
↓
扫描可用 skills,读取 name、description 和路径
↓
用户显式调用 skill,或 Codex 根据 description 自动匹配
↓
选中 code-review 后,加载完整 SKILL.md
↓
必要时读取 references、scripts、assets 等支持文件
↓
结合当前仓库、diff、测试日志等上下文执行审查
↓
输出结构化审查结果因此,Claude Code 和 Codex 在 Skill 本体上非常相似:二者都适合用 SKILL.md 表达一个完整、可复用的任务工作流。它们的主要差异不在 Skill 概念本身,而在默认目录、命令入口、运行环境和权限控制等平台机制上。
这里需要区分 Skill 和项目级指令文件。Claude Code 中的 CLAUDE.md、Codex 中的 AGENTS.md 更适合写项目长期约定,例如代码风格、目录结构、测试命令、依赖管理规则等;而 SKILL.md 更适合写某个具体任务的执行流程。对于 code-review 来说,项目级指令可以提供“本仓库怎么写代码”的背景,Skill 则负责“如何完成一次代码审查”。
4. Cursor:Skills 与 Rules 的分工
Cursor 也支持以 SKILL.md 为核心的 Skills。对于 code-review 这类多步骤工作流,可以放在项目内的:
.cursor/
└── skills/
└── code-review/
├── SKILL.md
├── examples/
│ └── review-output.md
└── scripts/
└── collect-diff.sh也可以尝试放在更通用的 .agents/skills/ 目录中,以便和其他支持 Agent Skills 标准的工具共享;但在 Cursor 中,.cursor/skills/ 通常是更直接、更稳妥的项目级位置,具体行为仍应以当前 Cursor 版本为准。
示例 SKILL.md:
---
name: code-review
description: Review changed code and pull requests for correctness, tests, security, maintainability, and project conventions.
---
# Code Review Skill
When reviewing changes:
1. Inspect the changed files and git diff.
2. Identify correctness, maintainability, security, and test coverage issues.
3. Group findings by severity.
4. For each finding, explain the problem, risk, and suggested fix.
5. If no blocking issue is found, summarize the main changes and remaining risks.Cursor 里的 Rules 仍然有价值,但更适合承载短规则和长期约束。如果 code-review 中有一些几乎每次代码任务都要遵守的项目规范,可以写成 Project Rule:
.cursor/
└── rules/
└── code-review.mdc示例:
---
description: Code review checklist for this repository
globs: **/*
alwaysApply: false
---
When reviewing code changes in this repository:
- Check correctness, edge cases, and regression risks.
- Check whether tests cover the changed behavior.
- Follow the existing architecture and naming conventions.
- Point out security risks such as secret leakage, unsafe input handling, or missing authorization.
- Return review comments grouped by severity.Cursor 的调用流程可以概括为:
用户在 Cursor 中打开项目
↓
Cursor 发现 .cursor/skills 或 .agents/skills 中的 Skill
↓
用户通过 /skill-name 显式调用,或 Agent 根据 description 判断是否使用
↓
必要时叠加 .cursor/rules 中的项目约束
↓
Agent 结合当前文件、选中代码、项目上下文和用户请求
↓
执行 code-review 工作流
↓
输出审查意见或修改建议因此,在 Cursor 中,code-review 更像是被拆成两部分:
工作流层:.cursor/skills/code-review/SKILL.md 或 .agents/skills/code-review/SKILL.md
规则层:.cursor/rules/code-review.mdcSkill 适合描述完整、可复用的代码审查流程;Rule 适合描述短小、稳定、经常需要注入的项目约束。对于旧的命令式工作流,也可以迁移为 Skill,让它拥有更清晰的触发说明和支持文件结构。
5. GitHub Copilot:面向仓库和 PR 流程的 Agent Skill
GitHub Copilot 也支持 agent skills。对于项目内的 code-review Skill,常见做法是放在 .github/skills 中:
.github/
└── skills/
└── code-review/
├── SKILL.md
├── examples/
│ └── review-comment.md
└── references/
└── repository-conventions.mdCopilot 也可以识别其他项目级 Skill 目录,例如 .claude/skills 和 .agents/skills。如果希望同一个 Skill 同时服务于 Copilot、Claude Code、Codex 等工具,可以优先考虑把公共 Skill 放在跨工具更容易复用的位置,再为不同平台补充必要的适配说明。
示例 SKILL.md:
---
name: code-review
description: Review pull requests and code changes for correctness, security, tests, and maintainability.
---
# Code Review Skill
When reviewing a pull request:
1. Read the PR diff and changed files.
2. Identify correctness, maintainability, security, and test coverage issues.
3. Prefer actionable comments with concrete file locations.
4. Avoid comments that only restate what the code does.
5. Group important findings by severity.Copilot 的调用场景更偏向 GitHub 协作流程,尤其是 PR review。它可以结合 PR diff、仓库上下文、custom instructions 和 agent skills 来生成审查意见。
这里需要区分三类文件:
.github/skills/code-review/SKILL.md:专项任务流程,适合代码审查、CI 失败排查、发布流程等需要按需调用的 Skill;.github/copilot-instructions.md:仓库级通用 instructions,适合几乎每次任务都要遵守的项目背景、构建命令和代码规范;.github/instructions/*.instructions.md或AGENTS.md:路径级或 Agent 级说明,适合更细粒度的上下文约束。
调用流程可以概括为:
开发者在 GitHub 或 IDE 中请求 Copilot 审查代码
↓
Copilot 获取 PR diff、changed files 和仓库上下文
↓
根据任务和 skill description 判断是否使用 code-review
↓
加载 .github/skills/code-review/SKILL.md 或其他受支持 Skill 目录中的 SKILL.md
↓
结合仓库 instructions、路径规则和 PR 上下文执行审查
↓
生成 review comments、suggested changes 或总结如果只是简单、长期、几乎每次任务都要遵守的规则,可以写在仓库级 instructions 中;如果是更完整、更专项的任务流程,则更适合写成 agent skill。
例如:
.github/copilot-instructions.md适合放通用规则:
When working in this repository:
- Follow the existing architecture and naming conventions.
- Prefer small, focused changes.
- Add or update tests when behavior changes.而下面这种更完整的任务流程,更适合放进 Skill:
.github/skills/code-review/SKILL.mdReview the PR diff, identify blocking issues, group findings by severity, and provide suggested fixes.6. 四个平台的放置方式与调用流程对比
| 对比项 | Claude Code | Codex | Cursor | GitHub Copilot |
|---|---|---|---|---|
| 更接近的形态 | 原生 Skill 包 | 原生 Skill 包 | Skill 包 + Rules 辅助 | Agent Skill + PR 流程 |
| 典型位置 | .claude/skills/code-review/SKILL.md | .agents/skills/code-review/SKILL.md | .cursor/skills/code-review/SKILL.md 或 .agents/skills/code-review/SKILL.md | .github/skills/code-review/SKILL.md |
| 核心文件 | SKILL.md | SKILL.md | SKILL.md,Rules 用 .mdc 补充长期约束 | SKILL.md |
| 主要触发方式 | 自动匹配或显式调用 | 自动匹配或显式调用 | /skill-name、@skill-name 或 Agent 按需选择;Rule 按配置注入 | PR review、Chat、Agent 或显式请求 |
| 选择依据 | Skill description 和用户任务 | Skill name、description 和用户任务 | Skill description、Rule 类型、路径和手动引用 | Skill description、PR 上下文和用户任务 |
| 加载内容 | SKILL.md 及支持文件 | SKILL.md 及支持文件 | SKILL.md、支持文件,以及匹配的 Rules | SKILL.md、支持文件、PR diff 和仓库上下文 |
| 适合场景 | 多步骤本地工程工作流 | CLI / IDE / App 中的工程任务沉淀 | IDE 内多步骤工作流和持续项目约束 | PR 审查、仓库协作、云端 Agent 任务 |
| 团队共享方式 | 随仓库提交 .claude/skills | 随仓库提交 .agents/skills | 随仓库提交 .cursor/skills、.agents/skills 和 .cursor/rules | 随仓库提交 .github/skills、.agents/skills 和 instructions |
| 主要注意点 | Skill 要聚焦,避免过大 | description 要清晰,避免误触发 | 区分 Skill 与 Rule:前者写流程,后者写短规则 | 区分通用 instructions 和专项 skills |
7. 一个 Skill 的通用调用流程
尽管不同平台的目录和命令不同,但一个 Skill 从“存在”到“被使用”,大致可以抽象为以下流程:
1. 放置
开发者把 Skill 放到平台约定目录中。
2. 发现
Agent 扫描可用目录,发现 Skill 或可复用规则。
3. 索引
Agent 读取 name、description、路径等轻量信息,用于后续匹配。
4. 选择
用户显式调用,或 Agent 根据任务描述自动判断是否需要使用。
5. 加载
Agent 读取完整说明文件,例如 SKILL.md、Rule 或 instructions。
6. 补充上下文
Agent 读取当前代码、diff、PR、测试日志、项目约定或支持文件。
7. 执行
Agent 按 Skill 中的步骤、检查清单和输出格式完成任务。
8. 输出
Agent 返回结构化结果,例如 review findings、修改建议、测试建议或 PR 评论。以 code-review 为例,四个平台都可以映射到这个流程:
公共任务:审查代码变更
↓
公共输入:diff / PR / changed files / tests
↓
公共步骤:读取变更 → 检查风险 → 分级输出问题 → 给出修复建议
↓
平台适配:
- Claude Code:加载 .claude/skills/code-review/SKILL.md
- Codex:加载 .agents/skills/code-review/SKILL.md
- Cursor:加载 .cursor/skills 或 .agents/skills 下的 SKILL.md,并叠加匹配的 Rules
- GitHub Copilot:加载 .github/skills、.agents/skills 等目录中的 SKILL.md,并结合 PR 上下文这样看,所谓“同一个 Skill 在不同平台中的调用差异”,主要不在任务本身,而在下面几件事:
- Skill 放在哪个目录;
- Agent 如何发现它;
- 用户如何显式触发它;
- Agent 是否能根据 description 自动选择它;
- Skill 被选中后加载哪些上下文;
- 最终输出进入本地对话、IDE 修改、PR 评论,还是云端 Agent 任务。
8. 最小公共 Skill 概念模型
为了让同一个 Skill 更容易迁移到不同平台,可以先设计一个平台无关的概念模型。这里的“最小公共”不是要求所有平台都支持同一种文件格式,也不是替代 P4 和 X2 中已经讨论过的 Skill 设计规范;它更像是一个中间层,用来把任务本身先描述清楚,再映射到各个平台的 SKILL.md、Rules、instructions 或其他承载机制。
name: code-review
description: >
Review code changes, diffs, or pull requests for correctness,
maintainability, security, tests, and project conventions.
when_to_use:
- 用户要求 review 当前代码变更
- 用户要求检查 PR 或 diff
- 用户准备合并代码前希望发现风险
inputs:
- diff
- changed_files
- pr_context
- test_logs
- repository_conventions
steps:
- 读取变更范围
- 理解变更意图
- 按 checklist 检查 correctness、tests、security、maintainability
- 按严重程度整理问题
- 给出可执行修复建议
checklist:
- correctness
- edge_cases
- maintainability
- security
- tests
- compatibility
- project_conventions
output_format:
- severity
- location
- problem
- reason
- suggested_fix
support_files:
- examples/review-output.md
- references/repository-conventions.md
- scripts/collect-diff.sh
platform_adapters:
claude_code:
path: .claude/skills/code-review/SKILL.md
trigger: 自动匹配 description 或显式调用 skill
codex:
path: .agents/skills/code-review/SKILL.md
trigger: 自动匹配 description 或显式调用 skill
cursor:
skill_path:
- .cursor/skills/code-review/SKILL.md
- .agents/skills/code-review/SKILL.md
rule_path: .cursor/rules/code-review.mdc
trigger: /skill-name、@skill-name、Agent 按需选择,或 Rule 按配置注入
github_copilot:
skill_path:
- .github/skills/code-review/SKILL.md
- .agents/skills/code-review/SKILL.md
- .claude/skills/code-review/SKILL.md
instructions_path:
- .github/copilot-instructions.md
- .github/instructions/*.instructions.md
- AGENTS.md
trigger: PR review、Chat、Agent 或显式请求这个结构的重点是先把“任务本身”抽象出来,再根据平台做适配。真正落地时,仍然应该优先遵守各平台当前支持的目录、frontmatter 字段和触发规则。
公共 Skill 层应该尽量稳定,包括任务目标、触发条件、输入输出、执行步骤、检查清单和输出格式。平台适配层则可以根据工具变化进行调整,例如目录位置、命令入口、是否支持自动触发、是否能读取 PR 上下文等。
小结
跨平台 Skill 互操作的关键,不是寻找一个所有工具都完全兼容的文件格式,而是识别出 Skill 中真正可复用的部分:
- 任务目标;
- 触发条件;
- 输入输出;
- 执行步骤;
- 检查清单;
- 示例;
- 支持文件;
- 输出格式。
Claude Code、Codex、Cursor 和 GitHub Copilot 都可以用 SKILL.md 表达专项工作流,只是默认目录、触发方式和上下文来源不同。Rules、instructions、AGENTS.md 等项目级文件更适合承载长期约束;Skill 更适合承载按需调用的任务流程。GitHub Copilot 则特别适合把 Skill 嵌入仓库协作、PR review 和云端 Agent 流程中。
因此,一个成熟的 Skill 不应该只写成“某个工具能读的文件”,而应该先写成平台无关的任务规范,再根据不同 Coding Agent 的机制做适配。这样,同一个 code-review Skill 才能在不同平台之间迁移、复用和演化。
下一期预告:P5 · 综合案例与度量——我们用一个完整的 Agent 产品案例,把 P1 到 P4 的所有概念串在一起:场景判断、知识库设计、记忆系统、Skill 管理。你会看到,从产品经理的视角,数据层的决策如何贯穿 Agent 产品的每一个环节。
欢迎各位老师在 https://github.com/datawhalechina/easy-data-x-ai 参与课程共建。
也欢迎各位老师加入 Data x AI 交流群~
